human_face_detect-1.1
human_face_detect-1.1
这篇博客写了复现esp-dl官方给的算例human_face_detect的过程和一些解决思路。
原文直接参考文档:
https://github.com/espressif/esp-dl/blob/release/v1.1/examples/human_face_detect/README_cn.md
https://docs.espressif.com/projects/esp-dl/zh_CN/release-v1.1/esp32s3/introduction.html#id4
需要补充的一点点shell知识
在windows中的powershell中,和ubuntu中的bash语法稍有不同。例如:
使用 Remove-Item 删除本地 esp-dl 文件夹:
`Remove-Item -Recurse -Force .\esp-d
驱动问题
当设备管理器中看到一个usb serial设备显示黄色感叹号时,证明电脑能读取到一个esp32s3设备但是没法正常通信,因此需要重新打驱动CH340(CH341是和340通用的)
windows:
https://www.wch.cn/downloads/file/65.html?time=2024-11-11%2016:23:41&code=NokOcQndbAiFrUztVEKcf1eZsx3x82vmIITMErTp
linux:
https://www.wch.cn/downloads/file/177.html?time=2024-11-11%2016:25:36&code=Dj3svYfYENNLKkggzMqECTTlDbDCGU8NUgONgvuE
安装即可识别。
对espressif的esp-dl官方教程的解释
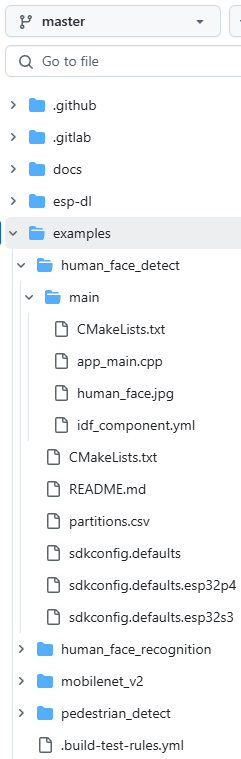
我从官方在线pdf版的教程进入,不管选择esp32s3的pre-release的master分支,还是release的release/v1.1分支(在线pdf版本中只有这两个分支的教程),只要从尝试模型库中的模型的人脸检测部分跳转,挑战后的内容实际都是根据release/v1.1写的。而本人也本着稳定使用的原则采用release/v1.1的版本,这两个库中的内容有很大区别,如下图对比。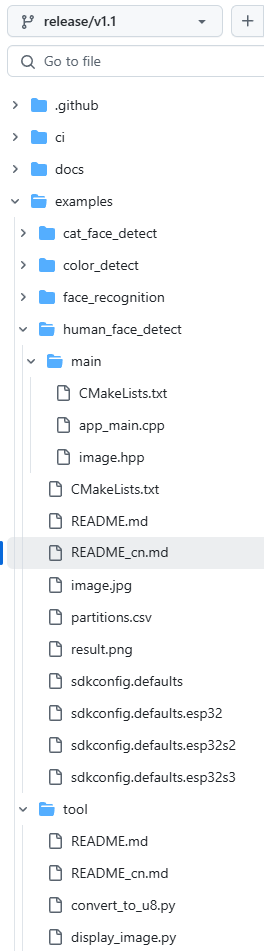
概述
1. 项目结构的模块化和标准化
- release/v1.1:
- 项目结构偏向传统的嵌入式开发方式,文件分布比较直接,比如有硬编码的头文件(
image.hpp)用于存储图像数据。 - 头文件、库、代码文件都需要显式地包含和链接。这使得项目更加紧密集成。
- 项目结构偏向传统的嵌入式开发方式,文件分布比较直接,比如有硬编码的头文件(
- master:
- 使用
idf_component.yml来管理项目中的依赖项,使得项目各个部分的开发和复用更加方便。这种方式更符合 ESP-IDF 的现代化组件标准,让项目更适合长期维护和扩展。
- 使用
2. 文件组织与依赖的简化
- 代码和头文件的变化:
- 在 release/v1.1 中,使用了
image.hpp直接嵌入图像数据,并不灵活。 - 在 master 中,删除了这种硬编码的做法,改为通过组件的方式(比如依赖
esp_jpeg)来处理图像,提供了更高的灵活性和解耦能力。
- 在 release/v1.1 中,使用了
- 库链接管理:
- 在 release/v1.1 中,
CMakeLists.txt中显式地对不同芯片类型进行静态库的链接管理,这使得项目对芯片的支持有了更多的控制,但也增加了代码的复杂性。 - master 版本不再显式链接多个库,而是通过组件管理自动处理。
- 在 release/v1.1 中,
3. 文件角色的变化
- 数据存储方式的变化:(这一点尤其重要,相信动手自己试过的朋友肯定能感受出来很大差异)
- **
image.hppvshuman_face.jpg**:- release/v1.1 使用
image.hpp将图像数据直接嵌入代码,这种方式可以让开发者快速测试模型,但不适合大规模使用。 - 在 master 中,示例图像文件(
Mona_Lisa.jpg)被直接作为文件嵌入项目。这表明新的结构倾向于从文件系统加载数据,而不是将数据硬编码。这种方式更通用,并且减少了对代码体积的影响。
- release/v1.1 使用
- **
总结:从紧耦合到模块化的转变
- release/v1.1 的设计更关注直接有效的嵌入式实现,适合于快速开发和验证。它的代码和数据紧耦合,所有内容都集中管理,但这也意味着不太灵活,且难以扩展和维护。
- master 的改进方向明显朝着现代嵌入式开发的最佳实践靠拢,重点在于模块化、复用性和自动化管理。通过使用组件化管理工具(如
idf_component.yml)和外部资源加载,它减少了手动配置的复杂性,使得项目更适合长期维护和功能扩展。
*.esp32s3配置文件替代性分析
基础配置:如果项目不需要使用特殊的 SPI RAM 模式(如 Octal 模式)或自定义分区表等高级配置,release/v1.1 的文件已经包含了基础的 CPU 频率和数据缓存设置,可以直接使用。
性能优化和兼容性:如果项目需要更高的性能(如特定的 SPI RAM 模式、闪存设置)或者兼容更高版本的 ESP-IDF(例如 5.4.0),那么可以参考 master 的配置文件。
sdkconfig.defaults文件只在编译过程中被读取,设置相应的编译选项。它们不需要读取文件夹或其他文件,也不会有相互依赖。
partitions文件变化
存储空间的变化:
- master 分支将
factory分区的大小从 2MB 增加到 8MB,这可能是为了给更大的应用程序提供足够的存储空间。
位于项目 main 目录中的CMakeLists.txt文件执行差异
Release/v1.1 执行过程:
- 组件注册:
idf_component_register会把所有的源文件(如app_main.cpp)和包含目录加入到编译过程中。- 因为有很多
include目录,编译器需要处理和查找多个模块的头文件。
- 静态库链接:
- 根据目标芯片(如
esp32s3),选择对应的库文件路径(libhuman_face_detect.a、libdl.a),并将这些库文件链接到项目中。 - 这些库文件提供了特定的功能,例如人脸检测算法。
- 根据目标芯片(如
- 总结:
- 这种方式适合需要多个模块和特定功能的复杂项目,因为它手动管理和链接了多个资源。
Master 执行过程:
- 组件注册:
- 只包含当前目录的源文件和头文件,非常简洁。
- 依赖的组件(如
esp_jpeg)是通过idf_component_register自动引用的,ESP-IDF 会在构建时处理这些依赖,减少手动配置的步骤。
- 嵌入文件:
- 有个嵌入的文件(
human_face.jpg),这意味着这个文件会被直接打包到程序中,便于在程序中直接访问。
- 有个嵌入的文件(
- 总结:
- 这种方式更模块化和简单,适合对依赖要求较少的项目,编译过程也会更快一些,因为引用的头文件和库更少。
yml文件
idf_component.yml 文件是用于模块化管理项目的组件和依赖,目的是为了使开发更加灵活和自动化。
执行过程
部署部分代码
1、修改代码后先删除原来的build文件夹
2、运行esp-idf的cmd或powershell快捷方式
本人桌面上的powershell快捷方式不知为何打开变成了cmd命令行,因此可以先执行下列代码完成环境配置:& "D:\language\Espressif\Initialize-Idf.ps1" -IdfId esp-idf-c1b3982edf7b5833f785c865a3465866
若读者也出现类似问题可以尝试找到自己esp-idf安装位置的ps1脚本进行同样的跳转
3、idf.py build创建build文件夹,也可同时选中esp32s3型号:idf.py -D IDF_TARGET=esp32s3 build
4、idf.py flash进行烧录
5、idf.py monitor监视esp32s3的输出;按ctrl+]退出监视终端
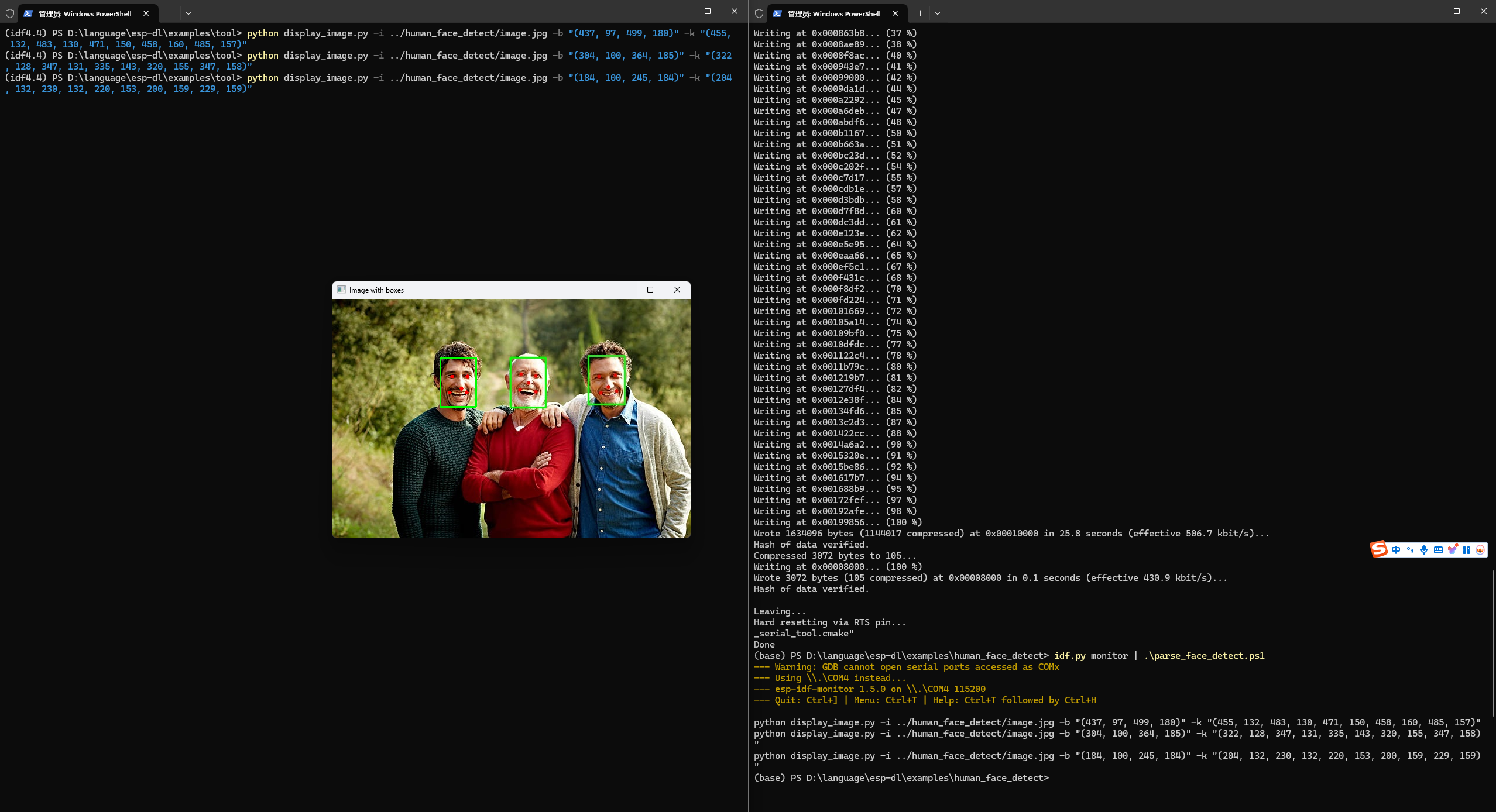
本人因为为了实现后续批注图片的编写性,因此这里执行idf.py monitor | .\parse_face_detect.ps1,后文会介绍功能
master部分
master部分可以直接执行成功,但因为我还没有太搞懂在不引用include文件夹中的各种hpp头文件的过程是怎么运行的,并且这是一个pre-release版本后续可能还会有官方改动,因此我没有尝试采用其他的图片。烧录成功后即进行下一部分的release/v1.1部分。
release/v1.1部分
hpp头文件问题:
执行遇到的第一个问题是如下图所示,可以看到是”\esp-dl\include\tool\dl_tool.hpp”出了问题: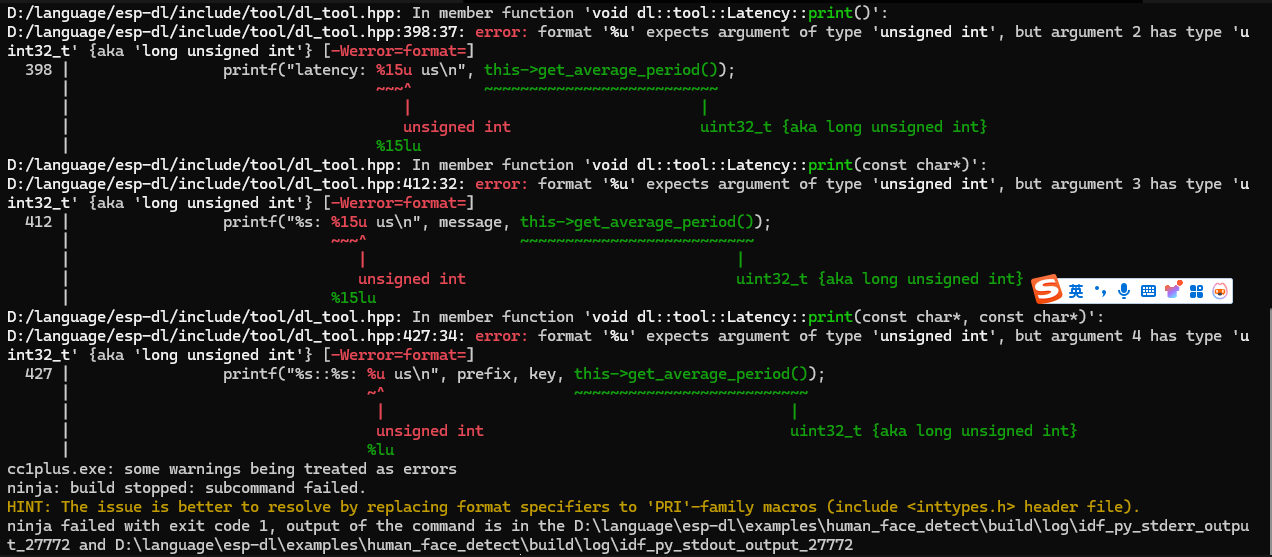
因此将对应的hpp头文件中的对应行进行如下修改:
增加包含头文件:#include <inttypes.h>
第399行改为:printf("latency: %" PRIu32 " us\n", this->get_average_period());
第413行改为:printf("%s: %" PRIu32 " us\n", message, this->get_average_period());
第428行改为:printf("%s:%s: %" PRIu32 " us\n", prefix, key, this->get_average_period());
虽然397、411、426行也有对应的语法,但是并未报错因此不做修改,否则会报错。
PSRAM初始化失败
错误信息:
1 | |
禁用PSRAM步骤:
执行idf.py menuconfig
- 进入
ESP PSRAM菜单:- 选择
ESP PSRAM --->选项。
- 选择
- 禁用 PSRAM 支持:
- 有一个选项
Enable PSRAM support或Support for external, SPI-connected RAM (PSRAM)。 - 将这个选项取消勾选,确保它是禁用状态。
- 有一个选项
第一种因为大小报错的情况:Flash 或分区表问题导致build过程报错
报错图如下: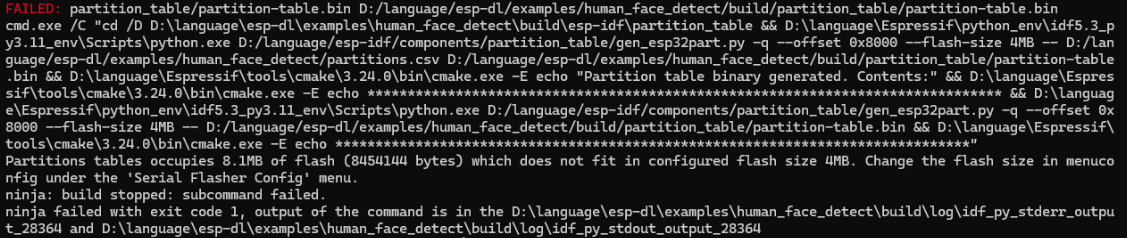
解决方法:
方法1:修改 Flash 大小配置
idf.py menuconfigSerial Flasher Config -> Flash size,将其改为更大的值,esp32s3根据型号等不同有两种最大闪存16MB或32MB。
按Esc退出,按y保存更改。
方法 2:调整分区表大小
如果按照方法1中,使用的硬件的 Flash 已经调整至最大值,则需要调整分区表以适配 Flash 容量。
将partitions.csv中的factory行(应用分区)最后一个值(其总大小)调整至至少比main文件夹大(因为占flash最大的部分是图片hpp文件)。
第二种因为大小报错的情况:能成功烧录但monitor循环报错
这种情况报错如下图所示,其前半部分绿色的参数部分输出是正常的,在该输出坐标的白色位置开始报错,结尾有大段关于build文件夹中路径的黄色报错,并且三部分反复循环,ctrl+]也无法关闭monitor界面,只能直接关闭终端。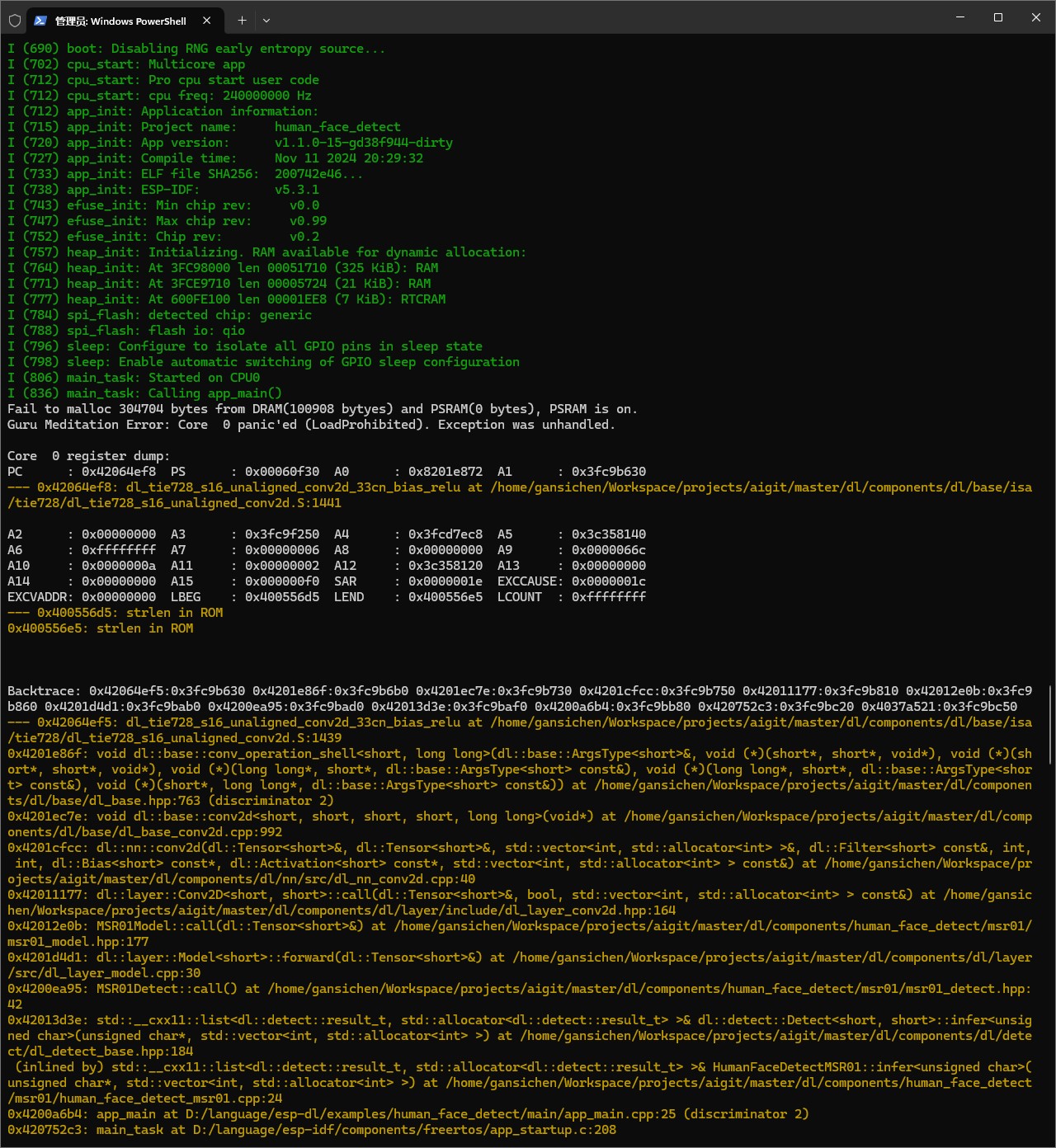
这种情况是因为本人一开始本人弄错了图片清晰度和尺寸的关系,一开始我以为只要将网上下载的图片处理到和示例蒙娜丽莎的大小40KB左右即可(这个处理实际上是降低清晰度的过程),但总是出现这种情况的报错,后来在观察从image.jpg生成的image.hpp文件大小时,发现需要将图片处理成宽度和高度都在约600px以下的图片才能完成正常识别。
图片处理网站:https://www.iloveimg.com/zh-cn/resize-image#resize-options,pixels
后续会自制离线能运行的cpp代码,方便编入esp32s3。
后续操作步骤简化
提取python命令
原文说打印检测结果的分数值和坐标值为如下时:
1 | |
运行如下标注命令:
1 | |
但这还需要繁琐的编辑,因此在这里编辑一个powershell脚本,可以实现python命令的自动输出,脚本如下:
1 | |
该脚本可以实现将任意数量的人脸输出结果中需要的参数提取,并输出下一步需要执行的python命令。如果是多张人脸则逐行输入各自独立的python代码,然后复制粘贴执行即可。
python命令改写
原库中的display图片的python脚本在多张人脸时,生成的第二张图中不会保留第一张图的批注痕迹,因此改为如下代码:
1 | |
该代码可以实现批注痕迹覆盖。
最终结果
最终结果如图所示,可以实现多张人脸的识别: