Data Wrangling
Data Wrangling
sed
sed 是 stream editor 的缩写,中文译为 流编辑器。它是一种强大的文本处理工具,可以在命令行下编辑文本文件或管道中的数据。
sed的常用命令格式
Bash
1 | |
选项:
-n: 静默模式,只有经过sed命令处理的行才会被输出。-e: 直接在命令行上进行sed的编辑。-f: 从指定文件中读取sed命令。-r: 支持扩展正则表达式。
命令:
s/pattern/replacement/: 搜索并替换,其中pattern是正则表达式,replacement是替换字符串。d: 删除行。p: 打印行。a\text: 在行后追加文本。i\text: 在行前插入文本。c\text: 用新文本替换行。n: 读取下一行,并输出pattern space中的行。g:global 的缩写,表示用于在同一行中对所有符合条件的子字符串进行全局替换。y:替换命令,两个字符集中的字符必须一一对应。
例如:sed 's/old/new/g' file.txt表示在每行行首添加“prefix_”。
第一段意思是去掉含有a或b的内容;第三段是去掉含有“ab”的内容;第二段失败是因为没有对小括号进行转义,-E是表明采用扩展正则表达式(可以理解为整句转义),也可以采用\(\)的方法。
正则表达式
假设有一个字符串 “Hello, World!”,那么:
.*可以匹配整个字符串 “Hello, World!”.*World可以匹配 “Hello, World”^.*World$可以精确匹配整个字符串 “Hello, World!”贪婪匹配: 默认情况下,
. *是贪婪匹配的,也就是会尽可能匹配更多的字符。非贪婪匹配: 如果想让它匹配尽可能少的字符,可以在
*后加?,变成.*?。匹配顺序: 正则表达式引擎是从左向右进行匹配的。一旦找到一个匹配
.*World的子串,它就会认为匹配成功,而不会继续向后查找。
正则表达式的常见模式:
.除换行符之外的 “任意单个字符”,即通配符。而.用专门的\.来表示。问号?同理。*匹配前面字符零次或多次+匹配前面字符一次或多次[abc]匹配a,b和c中的任意一个。(RX1|RX2)任何能够匹配RX1或RX2的结果^行首$行尾- 字符\d可用于代替0 到 9 之间的任何数字。
- 在正则表达式中使用的最常见空格形式是空格( ␣ )、_制表符( \t )、_换行符( \n ) 和回车符 ( \r )(在 Windows 环境中很有用),这些特殊字符可匹配其各自的空格。此外,空格特殊字符\s可匹配上述任何特定空格,
- \b,它匹配单词和非单词字符之间的边界。它在捕获整个单词时非常有用(例如,通过使用模式\w+\b)。

less
主要用于分页显示文件内容。
常用命令:
- 基本操作:
less filename: 打开文件- 空格键:向下翻一页
- b:向上翻一页
- G:跳到文件末尾
- g:跳到文件开头
- /pattern:向下搜索 pattern
- ?pattern:向上搜索 pattern
- n:重复上一次搜索
- N:反向重复上一次搜索
- 退出:
- q:退出 less
代码详解部分
示例1
cat ssh.log | sed -E 's/^.*Disconnected from (invalid |authenticating )?user (.*) [0-9.]+ port [0-9]+( \[preauth\])?$/\2/' | head -n100
正则表达式部分:
这是一个匹配 SSH 日志中特定行的正则表达式:
- **
^**:表示行的开头。 - **
.***:匹配任意数量的字符。 - **
Disconnected from**:匹配具体的 “Disconnected from” 这部分文本。 - **
(invalid |authenticating )?**:可选地匹配 “invalid “ 或 “authenticating “(有空格)。?表示这部分是可选的。这是第一捕获组,如果这部分存在就作为\1 - **
user (.*)**:匹配 “user “ 后的用户名,并捕获用户名为 **\2**。 - **
[0-9.]**:匹配 IP 地址中的数字和点号。 - **
port [0-9]**:匹配端口信息。 +:表示前面的表达式 必须至少出现一次,且可以多次出现。所以,**[0-9]+** 匹配的是由一位或多位数字组成的数字序列,即 1 位、2 位、3 位……或更多位的数字。如果只写成[0-9]而没有+,那么只能匹配一位数字的端口号,如0、1、9等。( \[preauth\])?:可选地匹配 “[preauth]”。这是第三捕获组,匹配可选的"[preauth]"部分。由于这部分不影响用户的提取,因此在替换时没有用到它。\2替换: 提取匹配的用户名,并作为最终输出。
**| head -n100**:- 将处理后的结果传递给
head,并只显示前 100 行。
示例2
正则表达式测试工具https://regex101.com/ 强烈推荐!!!/.* Disconnected from (invalid |authenticating )?user (.*)[^ ]+ port [0-9]+( \[preauth\])?$/gm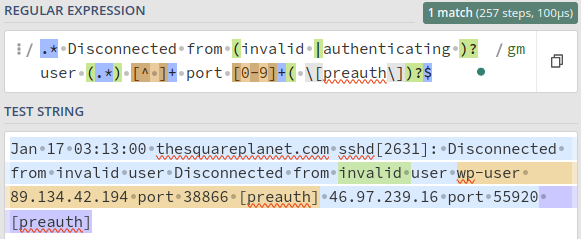
其中[^ ]表示除了空格以外的其他字符。这里不表示行首的原因是:
^在方括号(也称字符类)外表示行首,即匹配字符串的开头;在方括号内部表示取反,即匹配不属于该字符类的字符。例如:[^a-z]表示匹配非小写字母的字符。
我们可以发现此时用户名是“Disconnected from invalid user wp-user 89.134.42.194 port 38866 [preauth]”,但是因为**.*:** 这里的 . 是贪婪的,它会匹配尽可能多的字符。在匹配 “Disconnected from” 之后,它会一直匹配到字符串的结尾,除非后面的模式无法匹配。因此它把用户名截成了“wp-user 89.134.42.194 port 38866 [preauth]”。我们要修改它只需要添加?。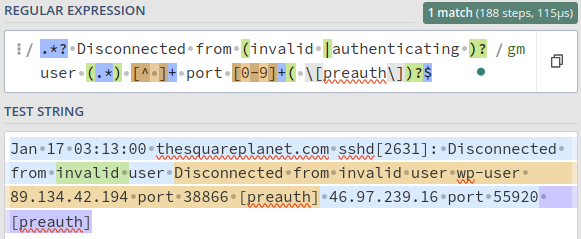
.*?: 这里的 ? 使 . 变得懒惰(lazy),这意味着它会匹配尽可能少的字符。在匹配 “Disconnected from” 之后,它会尽量匹配最少的字符,直到遇到下一个模式。因此它完整捕获了用户名。
但注意sed不支持该后缀,因此可以使用perl,例如perl -pe 's/.*?Disconnected from //'
其中
- -p: 命令行选项,表示对输入的每一行都执行一次表达式,并将结果输出。
- -e: 命令行选项,用于在命令行中直接执行Perl表达式。
wc
用于统计文本文件中的行数、字数和字节数。
基本用法
1 | |
- 文件名: 可以是单个文件,也可以是多个文件,甚至可以是通配符。
- 选项:
- -l: 统计行数
- -w: 统计字数(以空格分隔)
- -c: 统计字节数
- -m: 统计字符数(与 -c 相似,但处理多字节字符的方式不同)
- -L: 统计最长行的长度
sort
用于对文本文件进行排序的常用工具。
基本用法
1 | |
- 文件名: 可以是单个文件,也可以是多个文件,甚至可以是通配符。
- 选项:
- -r: 反向排序(降序)
- -n: 按数值排序
- -f: 忽略大小写
- -u: 去除重复行
- -t 分隔符: 指定字段分隔符,默认为空白字符
- -k POS1[,POS2]: 其中POS1: 排序开始的列或字符位置。POS2: 排序结束的列或字符位置(可选)。列号: 如果数据以特定的分隔符分隔(如逗号、空格),可以使用列号来指定排序范围。例如,
-k 2表示按第二列排序。字符位置: 如果数据没有明确的分隔符,可以使用字符位置来指定排序范围。例如,-k 5,10表示从第5个字符到第10个字符之间的文本作为排序键。例如:-k 3,5: 命令会提取每行数据的第3个到第5个字符作为排序的“键”。 - -o 输出文件: 将排序结果输出到指定文件
uniq
用于去除文本文件中重复行的工具。### 基本用法
1 | |
- 文件名: 可以是单个文件,也可以是多个文件,甚至可以是通配符。
- 选项:
- -c: 在每行前面显示重复的行数
- -d: 只显示重复的行
- -u: 只显示唯一的行
- -i: 忽略大小写
- -f N: 忽略前 N 个字段
- -s N: 忽略前 N 个字符
- -l:显示总行数。
awk
可以读取文本文件,逐行处理,并对每一行进行各种操作,包括提取、修改、过滤、统计等。适合对列操作。awk 的域分隔符(默认是空格,可以通过 -F 来修改)。
基本用法
1 | |
- 选项:
- -F 分隔符: 指定字段分隔符,默认为空白字符
- -v 变量=值: 设置变量的值
- pattern: 匹配模式,可以是正则表达式或条件表达式
- action: 要执行的命令或代码块
例如:例如:1
2
3
4
5
6
7
8
9
10
11# 打印文件 data.txt 的第二列
awk '{ print $2 }' data.txt
# 打印文件 data.txt 中包含 "apple" 的行
awk '/apple/ { print }' data.txt
# 计算文件 data.txt 的第三列的总和
awk '{ sum += $3 } END { print sum }' data.txt
# 将文件 data.txt 中的第二列和第三列互换
awk '{ temp = $2; $2 = $3; $3 = temp; print }' data.txt > new_data.txtawk '$1 == 1 && $2 ~ /^c.*e$/ {print $0}'中:~表示正则表达式匹配。^: 表示字符串的开头。**.*:** 匹配任意数量的任意字符(包括0个)。**$:** 表示字符串的结尾。$0表示整个当前行。awk 'BEGIN { rows = 0 } $1 == 1 && $2 ~ /^c.*e$/ {rows += 1} END {print rows}'BEGIN { rows = 0 }: 在处理输入数据之前,初始化一个变量rows,用于计数。{rows += 1}:如果两个条件都满足,则将计数器rows加1。
paste
将多个文件的内容按照列的形式拼接在一起,形成一个新的文件。
基本用法
1 | |
- 选项:
- -d <间隔字符>: 指定列与列之间的分隔符,默认为制表符。
- -s: 将每个输入文件的行合并为一行输出。
- -d’字符’: 指定多个分隔符,如-d’, ‘表示用逗号和空格作为分隔符。
bc
支持任意精度计算的语言。
- -i: 强制进入交互式模式,方便输入多条命令。
- -l: 定义使用的标准数学库,提供了更多的数学函数。
xargs
能将一个命令的输出作为另一个命令的参数。
xargs 的常用选项
- -n num: 指定每次传递给 command2 的参数个数。
- -p: 在执行命令前询问用户是否执行。
- -t: 在执行命令前打印命令行。
- -i{} 或 -I{}: 将 xargs 的每项名称替换为 {}。
- -d delimiter: 指定分隔符,默认是空格或换行符。
- -L num: 从标准输入一次读取 num 行送给 command 命令。
例如:1
2
3
4
5# 查找当前目录下所有 .txt 文件并删除
find . -name "*.txt" | xargs rm
# 将 find 命令的输出每一行作为参数传递给 echo 命令
find . -name "*.txt" | xargs echofind . -name "*.txt" | xargs -I {} mv {} {}.bak-I {}: 告诉xargs用{}来替换每个输入项。mv {} {}.bak中: - 第一个
{}: 代表要被重命名的原始文件名。它会根据find命令的输出,逐一替换为找到的每个 .txt 文件名。 - 第二个
{}: 同样代表原始文件名,但在这里,它会被加上.bak后缀,形成新的文件名。 - 例如
mv file1.txt file1.txt.bak,最后的文件名是原来整体的复制后加.bak。
ffmpeg
ffmpeg -loglevel panic -i /dev/video0 -frames 1 -f image2 - | convert - -colorspace gray - | gzip | ssh tsp 'gzip -d | tee copy.png' | feh -
-loglevel panic: 只显示致命错误信息-i /dev/video0: 从摄像头设备读取输入-frames 1: 只捕获一帧-f image2: 输出为图片格式- 最后的
-表示输出到标准输出而不是文件 - gray表示将图像转换为灰度图
- convert中第一个
-表示从标准输入读取 - convert中第二个
-表示输出到标准输出 gzip表示压缩数据流,gzip -d: 解压缩数据- 远程主机的名字叫做tsp,在tsp上执行
gzip -d | tee copy.png tee copy.png: 保存一份数据到copy.png文件,同时继续输出到标准输出feh -表示从标准输入读取图像并显示
这个命令链实现了从摄像头捕获一帧图像,转换为灰度图,在保存副本的同时显示图像的功能。
ssh甚至可以将cat /dev/video0的视频流实时传输到另一个服务器。
scp
用于在不同主机之间安全地复制文件和目录。基于SSH协议。
常用选项
- -r: 递归复制整个目录。
- -p: 保留源文件的权限、时间戳等属性。
- -P port: 指定SSH连接使用的端口号。
- -i identity_file: 指定私钥文件。
- -c cipher: 指定加密算法。
例如:假设你想将本地目录/home/user/documents中的所有文件复制到远程服务器192.168.1.100的/home/user/backup目录下,并保留所有属性,则:scp -r -p /home/user/documents user@192.168.1.100:/home/user/backup/
tr
常用选项
- -d: 删除字符集1中的所有字符。
- -s: 压缩重复字符。
- -c: 补集,即转换或删除字符集1中字符的补集。
- -t: 截断字符集1,使其与字符集2长度相同。
例如:echo "hello world" | tr 'a-z' 'A-Z'将小写字母转换为大写字母echo " hello world " | tr -d ' '删除所有空格
课后练习
2、统计 words 文件 (/usr/share/dict/words) 中包含至少三个 a 且不以 's 结尾的单词个数。这些单词中,出现频率前三的末尾两个字母是什么? sed 的 y 命令,或者 tr 程序也许可以帮你解决大小写的问题。共存在多少种词尾两字母组合?还有一个很 有挑战性的问题:哪个组合从未出现过?
答:
chatgpt:
1 | |
substr
substr(string, start, length) 这个函数在 awk 中有三个参数:
- string: 要进行截取的字符串。
- start: 开始截取的位置,从1开始计数。
- length: 截取的字符数。如果省略,则截取到字符串末尾。
comm
用于比较两个已排序的文件,前面的是文件1,后面的是文件2。
1 | |
claude:
1 | |
原理类似。
3、sed 原地替换的原理:
当使用 sed -i 's/REGEX/SUBSTITUTION/ input.txt' 这样的命令时,sed 实际上并不是直接修改原始文件。它的工作流程大致如下:
- 读取文件: sed 将
input.txt的内容读入内存。 - 执行替换: 根据提供的正则表达式和替换字符串,对内存中的内容进行修改。
- 写入临时文件: 将修改后的内容写入一个临时文件。
- 覆盖原文件: 删除原始的
input.txt,并将临时文件重命名为input.txt。
风险:
意外覆盖: 如果替换命令写错,或者正则表达式匹配不正确,可能会导致大量数据被意外删除或修改,无法恢复。
如何安全地进行文本替换:例如:sed 's/REGEX/SUBSTITUTION/g' input.txt > output.txt
4、找出您最近十次开机的开机时间平均数、中位数和最长时间。在 Linux 上需要用到journalctl,而在 macOS 上使用log show。找到每次起到开始和结束时的时间戳。
答:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123#!/bin/bash
echo "分析最近10次启动时间..."
# 使用单独的 --list-boots 来获取可用的启动记录
boot_count=$(journalctl --list-boots | wc -l)
if [ $boot_count -eq 0 ]; then
echo "未找到启动记录"
exit 1
fi
# 获取实际的启动时间数据,每次单独查询
times=()
# 初始化数组,用于存储每次启动的时间。
for i in $(seq 0 -1 -$((boot_count-1))); do
# 使用 --boot 参数查询每次启动
boot_time=$(journalctl --boot=$i | grep "Startup finished in" | grep -oP '[0-9.]+(?=s)' | tail -n1)
# seq 0 -1 -$((boot_count-1)):生成一个从 0 开始,步长为 -1,结束值为-boot_count+1的数字序列。这个序列的目的是为了从最新的启动记录开始逆序遍历,以便获取最近的boot_count次启动的时间。
if [ ! -z "$boot_time" ]; then
# 判断是否找到启动时间:如果boot_time不为空,则表示成功提取到了启动时间。
times+=($boot_time)
# 将启动时间添加到数组: 将提取到的启动时间添加到times数组的末尾。
# 如果已经收集了10条记录就退出
if [ ${#times[@]} -eq 10 ]; then
break
fi
# 限制记录数量:如果times数组中的元素个数达到了 10 个,说明已经收集了足够的数据,就跳出循环。
fi
done
# 检查是否获取到数据
if [ ${#times[@]} -eq 0 ]; then
echo "未能获取到任何启动时间数据"
exit 1
fi
# 计算总和用于平均值
sum=0
for t in "${times[@]}"; do
sum=$(echo "$sum + $t" | bc -l)
done
# 计算平均值
avg=$(echo "scale=2; $sum / ${#times[@]}" | bc -l)
# 排序数组用于计算中位数
IFS=$'\n' sorted=($(sort -n <<<"${times[*]}"))
unset IFS
# 计算中位数
mid=$((${#sorted[@]} / 2))
if [ $((${#sorted[@]} % 2)) -eq 0 ]; then
median=$(echo "scale=2; (${sorted[$mid-1]} + ${sorted[$mid]}) / 2" | bc -l)
else
median=${sorted[$mid]}
fi
# 找出最长时间
max=${sorted[-1]}
echo "分析结果:"
echo "平均启动时间: ${avg}秒"
echo "中位数启动时间: ${median}秒"
echo "最长启动时间: ${max}秒"
echo "总计分析了 ${#times[@]} 次启动记录"
先行和后行断言
- 正向先行断言:
(?=pattern)表示当前位置的后面必须匹配 pattern。 - 负向先行断言:
(?!pattern)表示当前位置的后面不能匹配 pattern。 - 正向后行断言:
(?<=pattern)表示当前位置的前面必须匹配 pattern。 - 负向后行断言:
(?<!pattern)表示当前位置的前面不能匹配 pattern。
例如:假设我们有一个字符串 “This is a test string.”,我们想匹配所有的 “is”,但是要求 “is” 后面必须跟着一个空格。则is(?= )
shell中的数组仍需后续继续学习!!!
5、1. 查看之前三次重启启动信息中不同的部分(参见 journalctl 的 -b 选项)。将这一任务分为几个步骤,首先获取之前三次启动的启动日志,也许获取启动日志的命令就有合适的选项可以帮助您提取前三次启动的日志,亦或者您可以使用 sed '0,/STRING/d' 来删除 STRING 匹配到的字符串前面的全部内容。然后,过滤掉每次都不相同的部分,例如时间戳。下一步,重复记录输入行并对其计数(可以使用 uniq )。最后,删除所有出现过 3 次的内容(因为这些内容是三次启动日志中的重复部分)。
答:
1 | |
6、
1 | |